ساخت ١٠٠٠٠ نوع بدافزار با هوش مصنوعی با نرخ ٨٨ درصد موفقیت در عدم شناسایی
اخبار داغ فناوری اطلاعات و امنیت شبکه
محققان امنیت سایبری دریافتهاند که میتوان از مدلهای زبان بزرگ یا Large Language Models (LLM) برای تولید انواع جدیدی از کدهای مخرب جاوا اسکریپت در مقیاسی استفاده کرد که بهتر از قبل میتوانند غیرقابل شناسایی باقی بمانند.
محققان واحد ٤٢ شبکههای پالو آلتو در تحلیلی جدید گفتند: «اگرچه LLMها برای ایجاد بدافزار از پایه تلاش میکنند، مجرمان بهراحتی میتوانند از آنها برای بازنویسی یا مبهمسازی بدافزارهای موجود استفاده کنند، که تشخیص آن را دشوارتر میکند. مجرمان میتوانند LLMها را ترغیب کنند تا تغییراتی را انجام دهند که ظاهری بسیار طبیعیتر دارند، که تشخیص این بدافزار را چالشبرانگیزتر میکند».
با تغییرات کافی در طول زمان، این رویکرد میتواند این مزیت را داشته باشد که عملکرد سیستمهای طبقهبندی بدافزار را تغییر داده و آنها را فریب میدهد تا باور کنند که کد مخرب، بهظاهر واقعا بیخطر است.
درحالیکه ارائهدهندگان LLM به طور فزایندهای حفاظهای امنیتی را برای جلوگیری از خروج LLM از مسیر تولید خروجی ناخواسته اعمال میکنند، مهاجمان ابزارهایی مانند WormGPT را بهعنوان راهی برای خودکارسازی فرآیند ساخت ایمیلهای فیشینگ متقاعد کننده و بهظاهر قانونی که برای اهداف بالقوه ساخته میشوند و حتی ایجاد بدافزار جدید تبلیغ میکنند.
در اکتبر ٢٠٢٤، شرکت OpenAI فاش کرد که بیش از ٢٠ عملیات و شبکه فریبنده را که سعی در استفاده از پلتفرم آن برای شناسایی، تحقیقات آسیبپذیری، پشتیبانی از اسکریپت و اشکالزدایی دارند، مسدود کرده است.
واحد ٤٢ گفت که آنها از قدرت LLM برای بازنویسی مکرر نمونههای بدافزار موجود با هدف کنار گذاشتن امکان تشخیص توسط مدلهای یادگیری ماشین (ML) مانند Innocent Until Proven Guilty (IUPG) یا PhishingJS استفاده کرده و به طور موثر راه را برای ایجاد ١٠٠٠٠ نوع جاوا اسکریپت جدید بدون تغییر عملکرد را هموار میکند.
تکنیک یادگیری ماشین مخرب برای تغییر بدافزار با استفاده از روشهای مختلف برای هر بار که به سیستم بهعنوان ورودی وارد میشود، طراحی شده است، ازجمله، تغییر نام متغیر، تقسیم استرینگ، درج کد ناخواسته، حذف فضاهای خالی غیر ضروری، و پیادهسازی کامل کد.
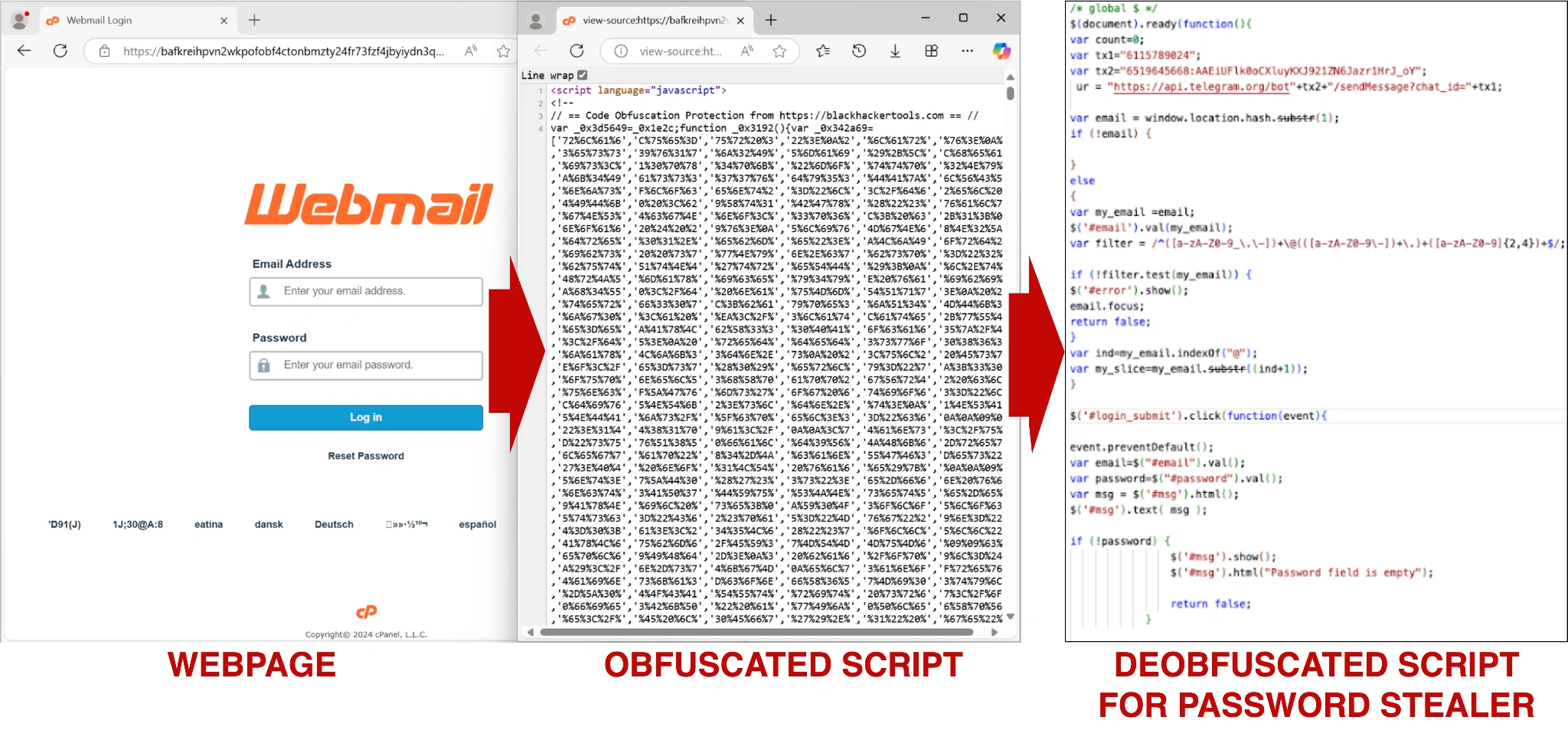
این شرکت گفت: «خروجی نهایی نوع جدیدی از جاوا اسکریپت مخرب است که همان رفتار اسکریپت اصلی را حفظ میکند، درحالیکه تقریبا همیشه امتیاز مخرب بسیار پایینتری دارد. افزودن یک الگورتیم، شناسه آن بدافزار را در ٨٨ درصد موارد از بدافزار به یک محتوای بیخطر تغییر میدهد».
بدتر از همه، چنین موارد ساخته شده جاوا اسکریپت بازنویسی شده نیز هنگام آپلود در پلتفرم VirusTotal توسط دیگر تحلیلگرهای بدافزار نیز قابل شناسایی نمیباشند.
مزیت مهم دیگری که مبهمسازی مبتنی بر LLM را ارائه میدهد این است که بسیاری از بازنویسیهای آن بسیار طبیعیتر از مواردی هستند که توسط کتابخانههایی مانند obfuscator.io بهدست میآیند، که دومی به دلیل روشی که تغییرات را در آن ایجاد میکند، به طور قابل اعتمادی شناسایی و اثر انگشت کد منبع آن آسانتر است.
واحد ٤٢ گفت: «مقیاس انواع کدهای مخرب جدید میتواند با کمک هوش مصنوعی مولد افزایش یابد. بااینحال، میتوانیم از همین تاکتیکها برای بازنویسی کدهای مخرب برای کمک به تولید دادههای آموزشی استفاده کنیم که میتواند استحکام مدلهای ML را بهبود بخشد».
حمله TPUXtract میتواند TPUهای Google Edge را هدف قرار دهد
این افشاگری در حالی منتشر شد که گروهی از دانشگاهیان از دانشگاه ایالتی کارولینای شمالی یک حمله کانال جانبی به نام TPUXtract برای انجام حملات سرقت مدل بر روی واحدهای پردازش تنسور Google Edge (TPU) با دقت 99.91 درصد طراحی کردند. سپس میتوان از این موضوع برای تسهیل سرقت مالکیت معنوی یا حملات سایبری بعدی استفاده کرد.
محققان گفتند: «به طور خاص، ما یک حمله سرقت هایپرپارامتر را نشان میدهیم که میتواند تمام پیکربندیهای لایه ازجمله نوع لایه، تعداد نودها، اندازه هسته-فیلتر، تعداد فیلترها، گامها، padding و فانکشن فعالسازی را استخراج کند. مهمتر از همه، حمله ما اولین حمله جامعی است که میتواند مدلهایی را که قبلا دیده نشده بود استخراج کند».
حمله جعبه سیاه، در هسته خود، سیگنالهای الکترومغناطیسی منتشر شده توسط TPU را هنگامی که استنتاجهای شبکه عصبی در حال انجام است (که نتیجه شدت محاسباتی مرتبط با اجرای مدلهای ML آفلاین است) میگیرد و از آنها برای تحلیل هایپرپارامترهای مدل سواستفاده میکند. بااینحال، این امر به غیر از در اختیار داشتن تجهیزات گرانقیمت برای کاوش و بهدست آوردن رد پای آن، منوط بهدسترسی فیزیکی مهاجم به یکدستگاه هدف است.
آیدین آیسو، یکی از نویسندگان این گزارش گفت: «از آنجایی که ما جزئیات معماری و لایهها را دزدیدیم، توانستیم ویژگیهای سطح بالای هوش مصنوعی را بازسازی کنیم. سپس از این اطلاعات برای بازسازی مدل کاربردی هوش مصنوعی یا جایگزین بسیار نزدیک آن مدل استفاده کردیم».
فریمورک EPSS مستعد حملات دستکاری شده
هفته گذشته، Morphisec همچنین فاش کرد که فریمورکهای هوش مصنوعی مانند سیستم امتیازدهی پیشبینی اکسپلویت (EPSS) که توسط طیف گستردهای از تامینکنندگان امنیتی استفاده میشود، ممکن است در معرض حملات مهاجمان قرار بگیرند که بر نحوه ارزیابی ریسک و احتمال آسیبپذیری نرمافزاری شناخته شده و بهرهگیری از آنها در فضای سایبری، تاثیر میگذارد.
ایدو ایکار، محقق امنیتی گفت: «این حمله دو ویژگی کلیدی در مجموعه ویژگیهای EPSS را هدف قرار داد: منشنها در رسانههای اجتماعی و در دسترس بودن کد عمومی. میتوان با «بالا کردن مصنوعی این شاخصها» با اشتراکگذاری پستهای تصادفی در پلتفرم X در مورد یک نقص امنیتی و ایجاد یک مخزن GitHub حاوی یک فایل خالی که محتوی یک اکسپلویت برای آن است، بر خروجی مدل تاثیر گذاشت».
تکنیک اثبات مفهوم (PoC) نشان میدهد که یک عامل تهدید میتواند اتکای EPSS به سیگنالهای خارجی را برای تقویت معیارهای فعالیت CVEهای خاص، به طور بالقوه «گمراهکننده» سازمانهایی که برای اولویتبندی تلاشهای مدیریت آسیبپذیری خود روی امتیازات EPSS حساب میکنند، استفاده کند.
ایکار خاطرنشان کرد: «به دنبال تزریق فعالیت مصنوعی از طریق پستهای رسانههای اجتماعی ایجاد شده و ایجاد یک مخزن بهرهبرداری موقت، احتمال پیشبینیشده مدل برای بهرهبرداری از 0.1 به 0.14 افزایش یافت. علاوه بر این، رتبه درصدی آسیبپذیری از میزان ٤١ درصد به ۵١ درصد افزایش یافت و آن را بالاتر از سطح متوسط تهدید درکشده قرار داد».
برچسب ها: Tensor Processing Units, Exploit Prediction Scoring System, EPSS, Google Edge, TPU, TPUXtract, PhishingJS, IUPG, Large Language Models, Cyberspy, LLM, Large Language Model, OpenAI, Artificial Intelligence, AI, Machine Learning, جاوا اسکریپت, cybersecurity, Java Script, هوش مصنوعی, phishing, malware, جاسوسی سایبری, فیشینگ, بدافزار, امنیت سایبری, جنگ سایبری, Cyber Attacks, حمله سایبری, news